4D AI Fluency Lab
A local Model Context Protocol server that measures, tracks, and develops AI fluency through behavioral assessment of Claude conversations. Classifies prompts against a 4-dimensional rubric, generates HTML reports, trains learners with interactive exercises, and lets coaches run structured programs without leaving Claude Code.
what it does
Classify
Score any Claude conversation against the 4D rubric: every user prompt, all four dimensions, sub-behavior tags.
Report
Self-contained HTML reports with radar charts, score breakdowns, dimension insights, and shareable PNG cards.
Train
Duolingo-style trainer built from the learner's own classified conversations: XP, hearts, streaks.
Coach at Scale
Generate turnkey champion packets a coach can run without education team involvement.
Track Progress
Compare any two profiles, see score deltas per dimension, and visualize trends over time.
Cohort Analytics
Group reporting: tier distribution, weakest shared dimension, outlier detection across a team.
architecture
the 4d rubric
Delegation
What the user delegates vs. keeps, from handing off the full task to setting goals and constraints.
Description
How much the user specifies product, process, and performance constraints.
Discernment
Whether the user builds in evaluation structure: asks for alternatives, flags uncertainty.
Diligence
Responsibility signals: deployment context, privacy, ethics, accountability, transparency.
scoring & tiers
Foundation
avg < 1.0
Prompt-level thinking. Delegates tasks but provides minimal constraints or evaluation structure.
Practitioner
avg 1.0–1.99
Growing fluency. Starting to specify outputs and occasionally ask for alternatives or flag uncertainty.
Expert
avg ≥ 2.0
Full fluency. Frames work as goals, specifies constraints, builds in accountability and evaluation.
tool suite 20+ MCP tools
Assessment
5Reports & Training
4Cohort Analytics
3Champion Enablement
2Content Management
2Session Import
2Rubric
3slash commands
Browse Claude Code sessions, pick one, score it, view the report
Paste a claude.ai export and classify it against the rubric
Browse all Claude Code sessions organized by project
Open a generated HTML report for any stored profile
Compare two most recent profiles and surface score deltas
Generate an interactive Duolingo-style game from a profile
Generate a turnkey champion success packet for a learner
Log champion observations after a coaching session
Content health dashboard: what's fresh vs. stale
Check rubric version and surface key changes
generated outputs
Full HTML Report
report-{id}.html
- -Radar chart across all 4 dimensions
- -Score bar per dimension (0–3 scale)
- -Diligence signal breakdown
- -Insights panel with course links
- -Monthly prompt volume + score trend chart
Shareable Card
share-{id}.html
- -Dark theme, 600px wide
- -Downloadable as PNG via html2canvas
- -Overall score /3.0
- -Dimension bars + radar
- -Monthly trend visualization
Trainer Game
trainer-{id}.html
- -XP system: Foundation → Practitioner → Expert
- -3 hearts per session, streak tracking
- -Mastery: prompts retire after 3 correct
- -Round types: spot_upgrade, what_changed, tag_dimensions
Champion Packet
packet-{id}.html
- -Dual-tab: Champion Guide + Learner Deep Dive
- -Pre-scored conversation examples
- -Coaching frameworks per dimension
- -Turnkey, no education team needed
output samples
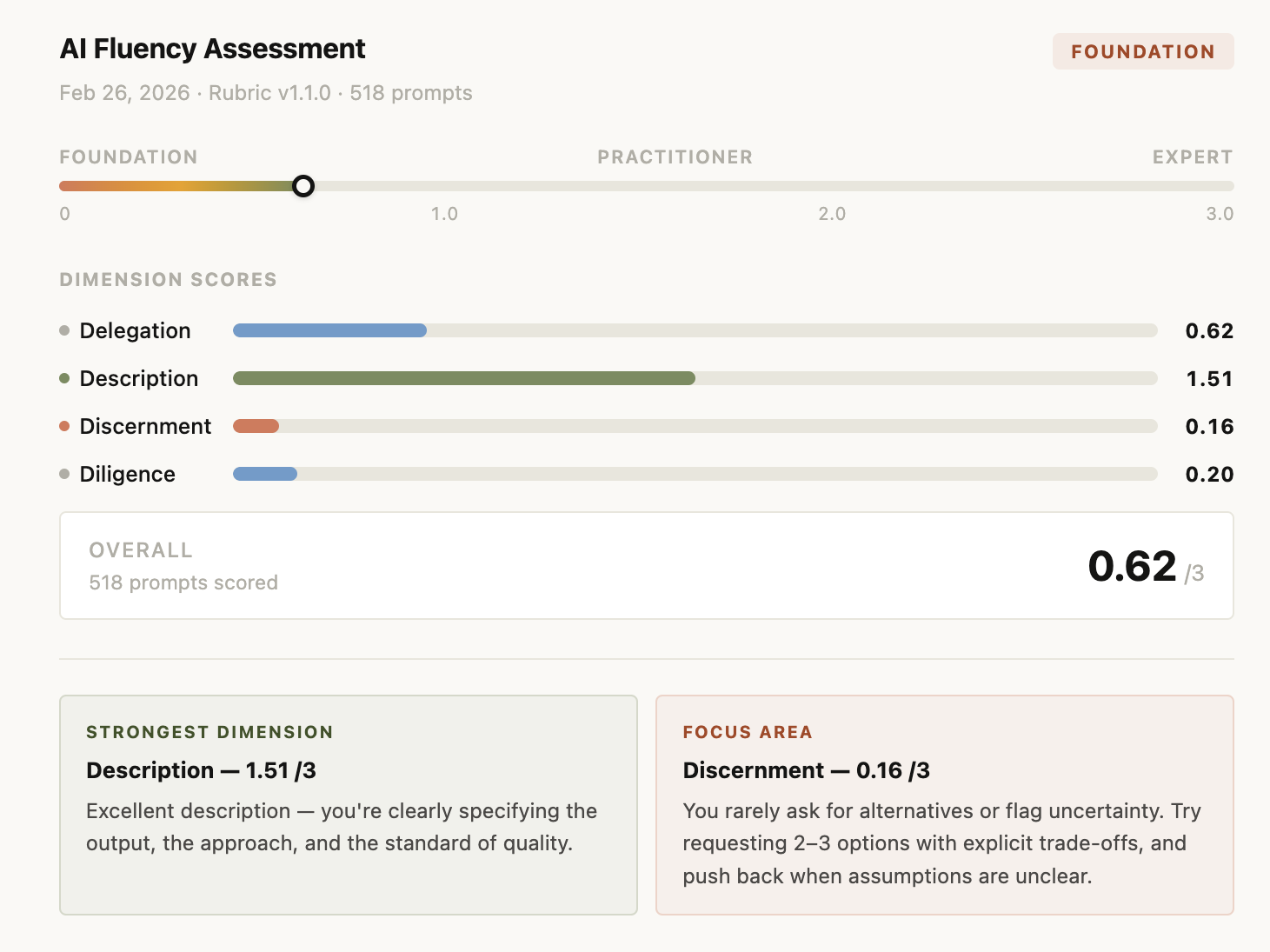
generated HTML report: dimension score bars (Delegation, Description, Discernment, Diligence), overall score out of 3.0, and strongest / focus area cards
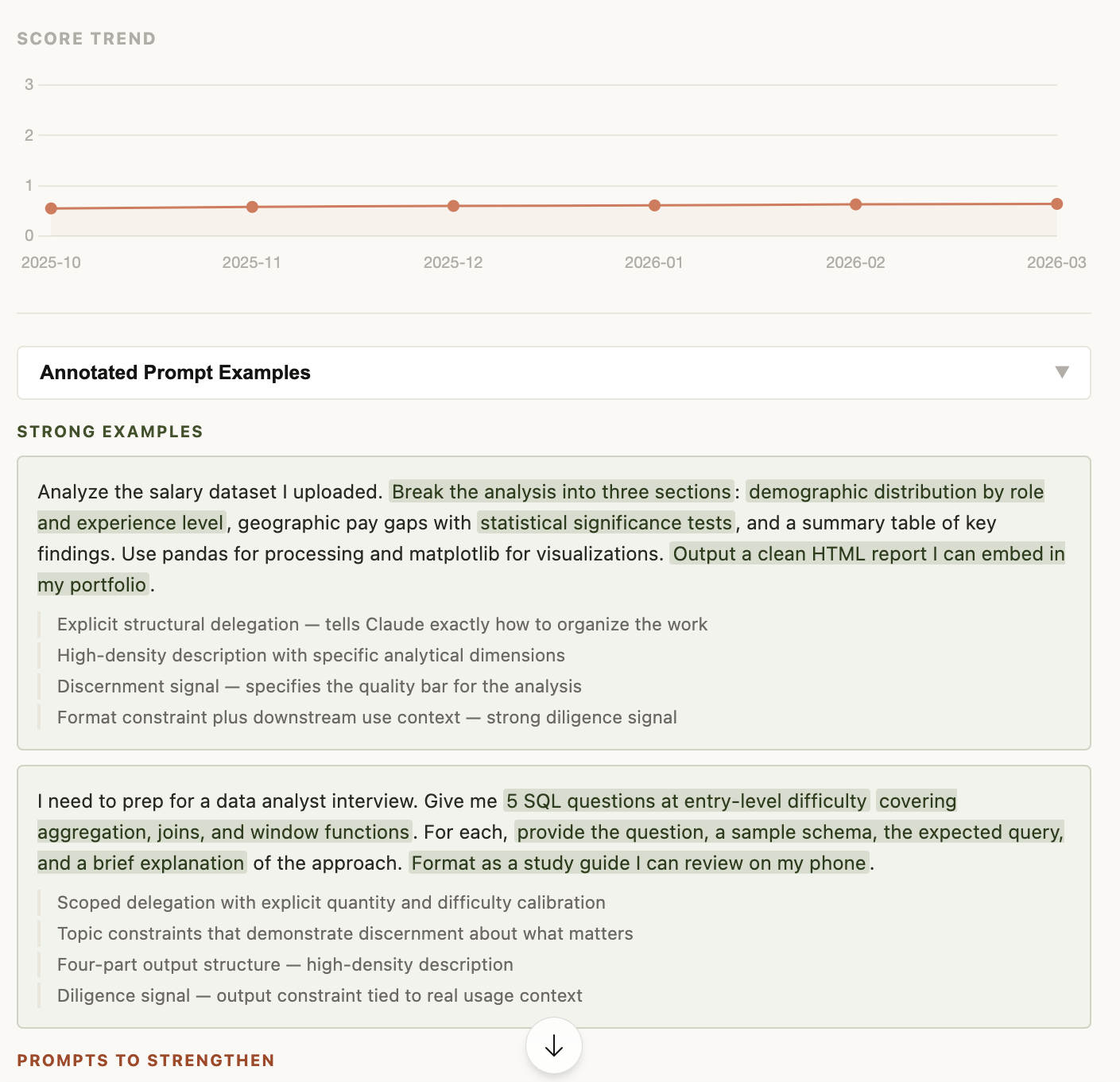
monthly score trend line and annotated prompt examples. strong prompts are highlighted by behavior tag showing exactly which signals drove the score

prompts to strengthen: each weak prompt is annotated with what's missing, paired with a strengthened rewrite that adds delegation structure, output constraints, and diligence signals
end-to-end run inside Claude Code: session selection, rubric scoring, and HTML report generation all from a single /classify command
tech stack
| Layer | Technology | Note |
|---|---|---|
| Runtime | Node.js + TypeScript | compiled via tsc |
| MCP | @modelcontextprotocol/sdk | stdio transport |
| Database | SQLite via better-sqlite3 | WAL mode, FK constraints on |
| Reports | Self-contained HTML + Chart.js | no external dependencies |
| Share Cards | html2canvas | downloadable PNG |
| Validation | Zod schemas | all tool inputs validated |
| HTTP | localhost:3131 | serves generated HTML reports |
database schema
All multi-table inserts use transactions. WAL mode enabled. Every profile, artifact, and assessment item is permanently tagged with the rubric version it was scored against.